WikiLLM:基于 Andrej Karpathy 理念的 AI 自主个人知识库
WikiLLM
利用 LLM 构建个人知识库的系统。WikiLLM 将原始素材”编译”成结构化、交叉链接的高质量中文 Wiki,可在 Obsidian 中查看。
本项目基于 Andrej Karpathy 提出的理念构建。详见:LLM Knowledge Bases

项目概述
WikiLLM 的工作流包括:
- 数据摄入:源文档(文章、论文、代码库、数据集、图像)被索引到
raw/目录 - Wiki 编译:LLM 增量地”编译”原始数据成 markdown 文件的 wiki,包含摘要、反向链接、分类概念和相互链接的文章
- IDE:Obsidian 用作前端查看原始数据、编译后的 wiki 和可视化
- 问答:LLM 可以通过研究相关数据来回答针对 wiki 的复杂问题
- 输出:结果渲染为 markdown 文件、Marp 幻灯片或 matplotlib 图像,可在 Obsidian 中查看
- Linting:LLM”健康检查”发现不一致、填补缺失数据、建议新文章候选
- 额外工具:诸如 wiki 上的朴素搜索引擎等额外工具
核心原则
- LLM 编写和维护所有 wiki 数据;手动编辑很少见
- 用户探索和查询被归档回 wiki 以增强它
- 系统专注于 markdown 文件和 Obsidian 兼容格式
- 图像被下载到本地 以便 LLM 轻松引用
目录结构
wikillm/
├── raw/ # 源文档和未处理数据
├── wiki/ # LLM 编译的 markdown wiki
│ ├── concepts/ # 核心概念文章
│ ├── practices/ # 实践指南文章
│ ├── visual/ # 可视化内容
│ ├── queries/ # 查询存档
│ ├── assets/ # 图像和资源文件
│ ├── INDEX.md # 首页索引
│ └── Glossary.md # 术语表
├── skills/ # Claude Code 技能
├── CLAUDE.md # 项目特定的 Claude 指令
└── README.md # 本文件
当前内容
本 wiki 当前包含关于 Harness Engineering 的综合知识库,基于以下来源编译:
- OpenAI - Harness Engineering:在智能体优先的世界中利用 Codex
- Anthropic - Harness design for long-running application development
- Martin Fowler - Harness engineering for coding agent users
- LangChain - Improving Deep Agents with harness engineering
- NxCode - Harness Engineering: The Complete Guide
- MiniMax - MiniMax M2.7: Early Echoes of Self-Evolution
- Mitchell Hashimoto - My AI Adoption Journey
快速开始
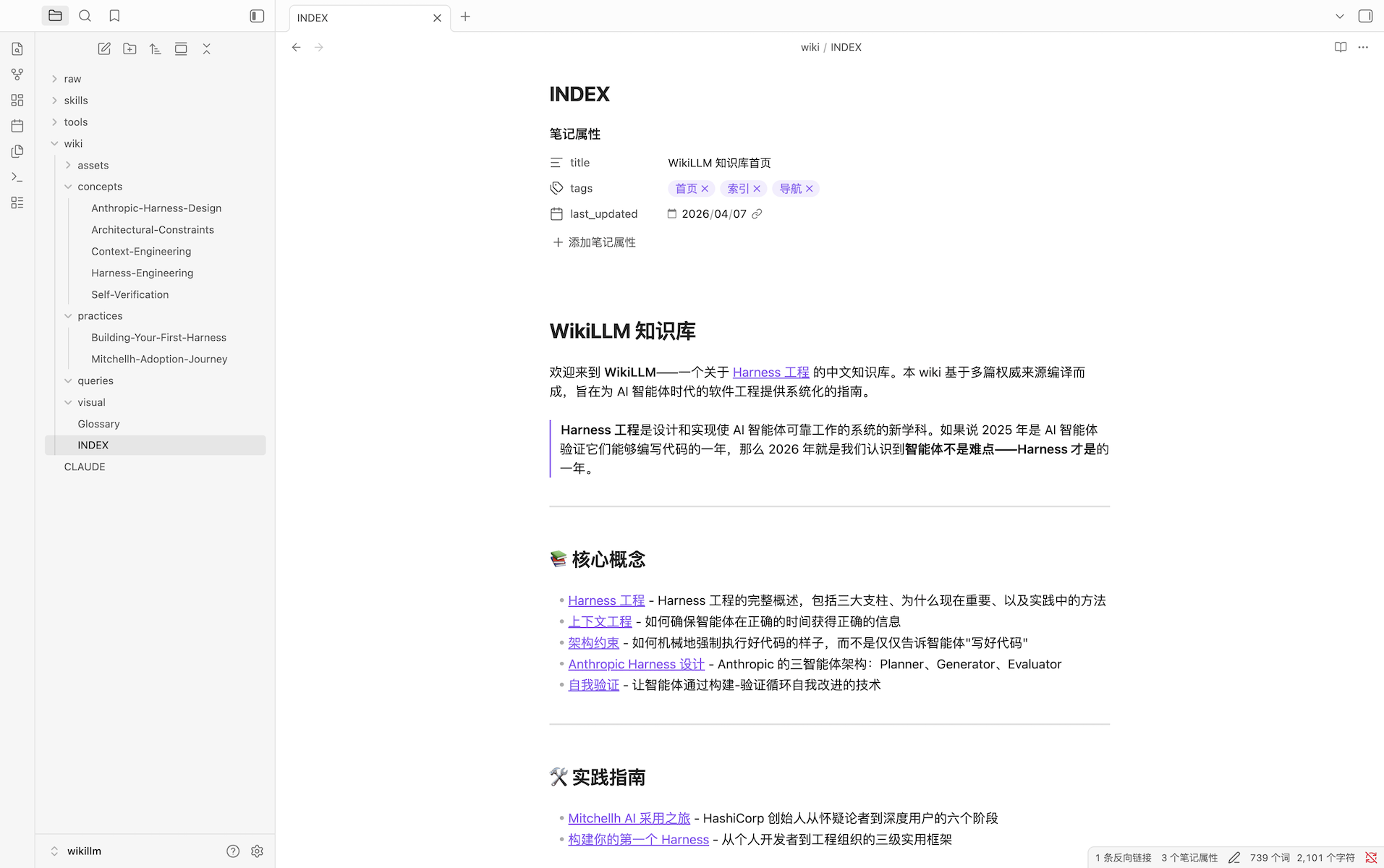
在 Obsidian 中查看
- 下载并安装 Obsidian
- 在 Obsidian 中打开本仓库作为 vault
- 从
wiki/INDEX.md开始探索
使用技能
本项目包含 Claude Code 技能用于生成 wiki:
# 在 Claude Code 中
/skills wiki 编译
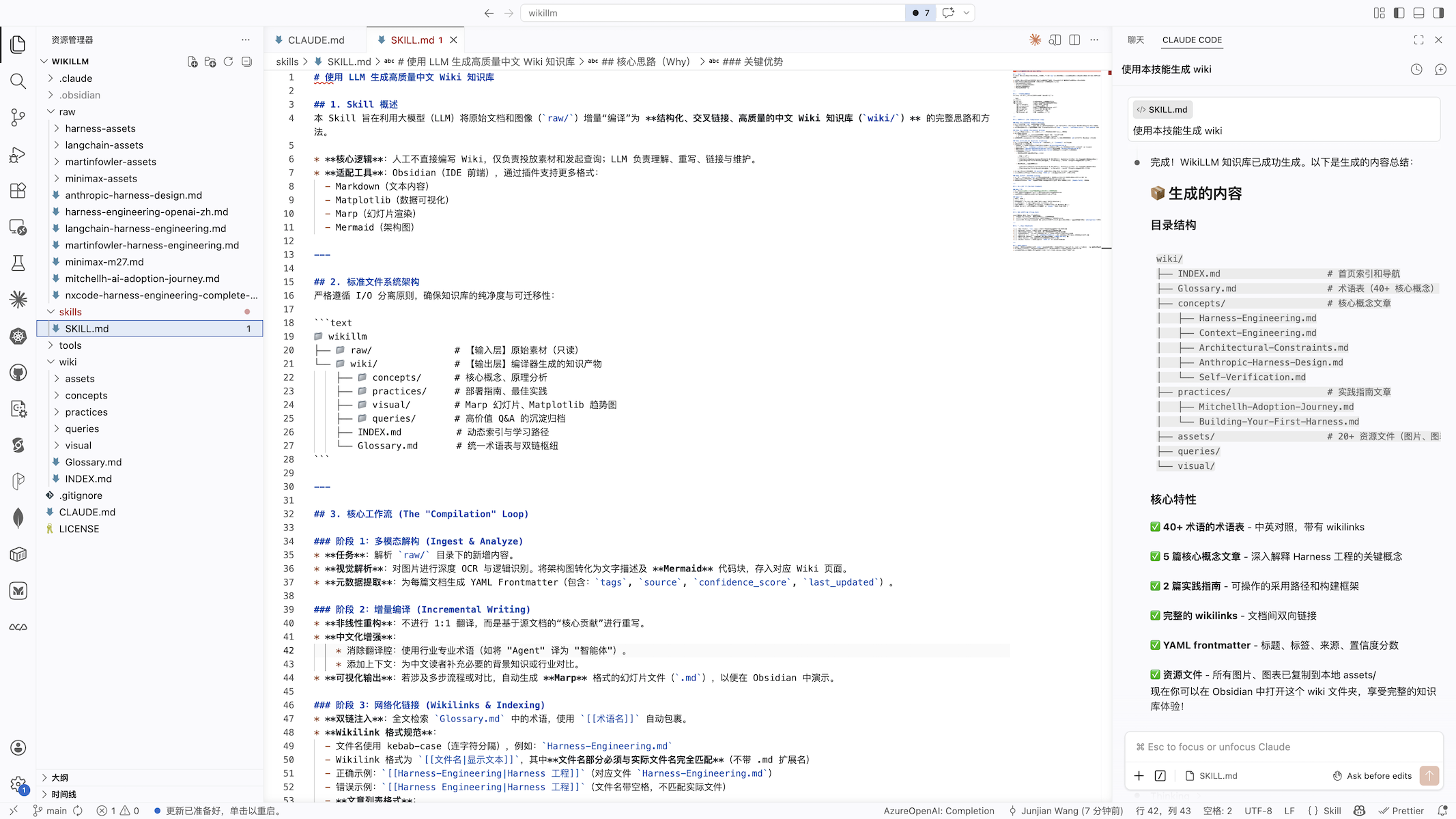
详细说明请参阅 skills/SKILL.md。
Andrej Karpathy: LLM Knowledge Bases
最近我发现一个非常实用的方法:利用大语言模型(LLM)为各类感兴趣的研究方向搭建个人知识库。这样一来,我近期消耗的模型令牌中,用于处理代码的占比大幅减少,更多被用于处理知识(以 Markdown 文件和图片形式存储)。
最新的大语言模型在这方面表现十分出色。具体做法如下:
数据导入
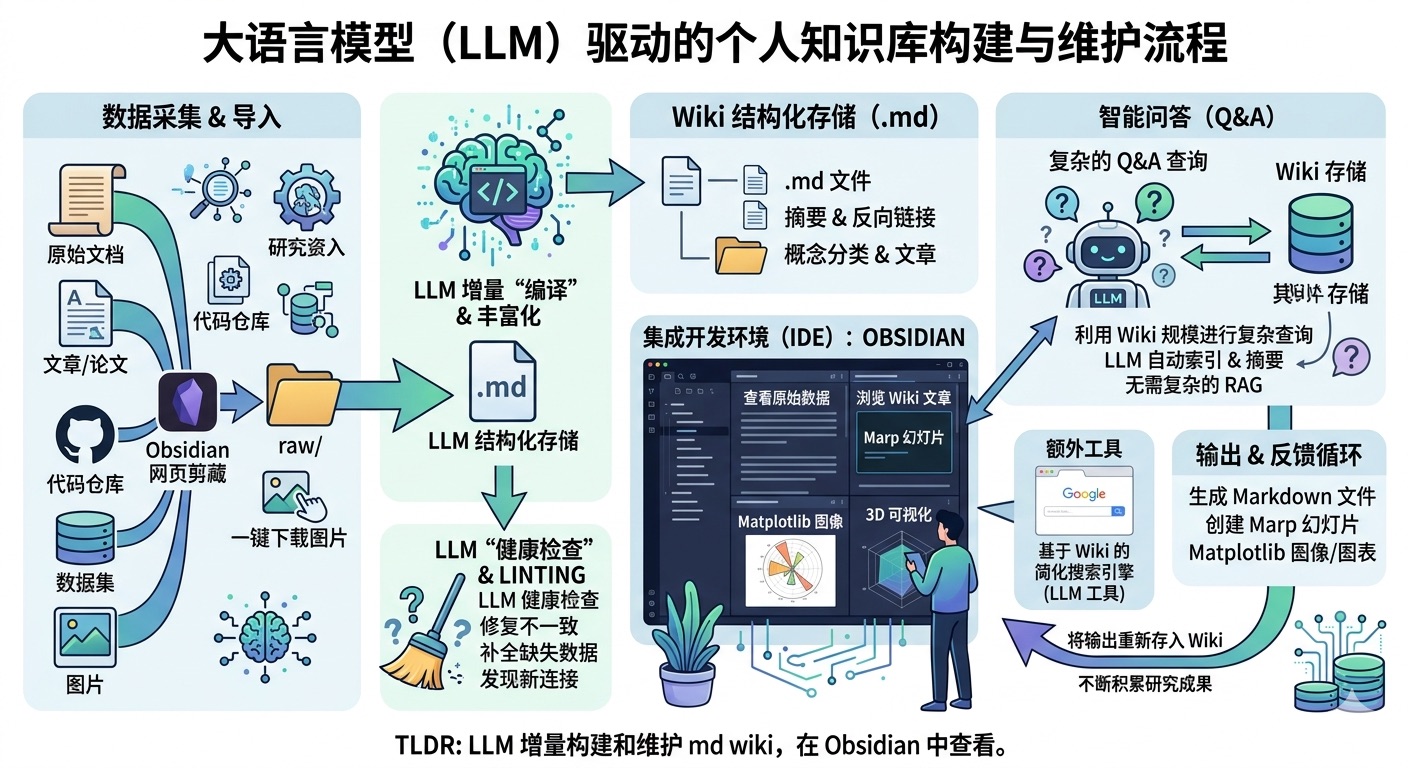
我先将各类源文件(文章、论文、代码仓库、数据集、图片等)归档到 raw/ 目录下,再通过大语言模型逐步“编译”生成一份知识库,这份知识库本质就是按目录结构组织的一系列 .md 文件。
知识库会包含 raw/ 目录下所有数据的摘要、反向链接,还会将数据按概念分类、撰写对应词条并完成相互关联。
为把网页文章转为 .md 文件,我习惯使用 Obsidian 网页剪藏插件,同时通过快捷键将相关图片批量下载到本地,方便大语言模型直接调用。
集成开发环境
我把 Obsidian 当作前端 IDE,既能查看原始数据、编译后的知识库,也能查看衍生的可视化内容。 需要重点说明的是:整个知识库的内容撰写与维护均由大语言模型完成,我几乎不直接手动修改。我还试用过多款 Obsidian 插件,以其他形式渲染和查看数据(比如用 Marp 制作幻灯片)。
问答交互
真正有意思的是,当知识库规模足够大时(比如我近期的研究知识库已有约 100 篇词条、40 万字),就可以向大语言模型智能体提出各类复杂问题,它会自主检索、梳理并给出答案。 我原本以为需要用上复杂的检索增强生成(RAG)技术,但在当前这种小规模场景下,大语言模型能自动维护索引文件和所有文档的精简摘要,轻松读取全部关键相关数据,效果已经很好。
结果输出
我不满足于仅在文本或终端获取答案,更倾向于让模型直接生成 Markdown 文件、幻灯片(Marp 格式)或 Matplotlib 图表,所有内容都能在 Obsidian 中查看。 根据不同查询需求,还可以生成更多种可视化格式。通常我会把这些输出结果“归档”回知识库,进一步丰富内容,让后续的查询和探索持续为知识库积累价值。
内容校验
我会让大语言模型对知识库进行“健康检查”,比如排查数据矛盾、通过联网搜索补全缺失信息、挖掘潜在关联以生成新词条候选等,逐步优化知识库、提升整体数据完整性。大语言模型还很擅长提出值得进一步探究的问题。
辅助工具
我还自行开发了一些数据处理工具,比如快速编写了一个简易的知识库搜索引擎,既可以通过网页界面直接使用,也更常通过命令行接口(CLI)将其作为工具交给大语言模型,用于处理更复杂的查询。
后续探索
随着知识库仓库不断扩容,自然而然会考虑结合合成数据生成与模型微调,让大语言模型通过模型权重“真正记住”这些数据,而不只是依赖上下文窗口。
总结
从多个来源收集原始数据,由大语言模型编译为 Markdown 格式知识库;再通过各类命令行工具驱动大语言模型完成问答,并逐步完善知识库,所有内容均可在 Obsidian 中查看。几乎无需手动编写或编辑知识库,全程由大语言模型主导维护。我认为这一方向完全有潜力诞生一款出色的新产品,而非目前这种零散脚本的组合方案。